模块和库
模块的概念
前面的练习中,我们的例子都是一个Python代码文件就实现了功能。
那是因为现在我们实现的功能都比较简单,一个代码文件就够了。
如果大家进入到企业里面,成为一名苦逼程序猿,就可以发现,我们要开发的系统会复杂的多。需要开发的代码长达上万行,甚至数十万行、数百万行。
这么多的代码放在一个代码文件里显然是不合理的。
项目开发的的代码文件,可能有成百上千个。
不同的代码文件,实现了不同的功能模块,就像一块块积木一样。这些功能模块文件最后合起来,实现了一个完整的软件。
所以,在Python中,一个代码文件(也就是一个.py文件),我们也叫它一个模块(Module)。
比如
a.py 文件,我们就可以称之为模块a,
b.py 文件,我们就可以称之为模块b
模块之间的调用
那么模块之间是怎么互相联系的呢?
我们来看一个例子。
几个同事午餐经常一起去饭店聚餐,我们开发一个程序,记录每人的账单,月末可以结算
我们可以把 输入总费用和聚餐人员,计算人均费用 的功能,单独实现在一个模块文件 aa.py, 其内容如下
fee = input('请输入午餐费用:')
members = input('请输入聚餐人姓名,以英文逗号,分隔:')
# 将人员放入一个列表
memberlist = members.split(',')
# 得到人数
headcount = len(memberlist)
# 计算人均费用
avgfee = int (fee) / headcount
print(avgfee)
好了,人均费用计算比较简单。
但是我们还需要将每次账单 记录到文件中,这样才好定期结算。
我们可以创建另外的一个模块文件 save.py。 在里面定义一个函数, 该函数实现记录消费信息到文件功能。 其内容如下
def savetofile(memberlist, avgfee):
with open('record.txt','a',encoding='utf8') as f:
# 通过列表推导式,产生 人:费用 这样的列表
recordList = [f'{member}:{avgfee}' for member in memberlist]
f.write(' | '.join(recordList) + '\n')
方法一
在aa.py里面 通过import关键字导入模块save ,
这样save 就成了模块 aa 里面的的一个变量,这个变量指向的是一个 模块对象
不要感到奇怪,在Python中, 模块 也是一个对象。
这样我们就可以通过save.savetofile 访问到 save模块里面的函数
完整代码如下:
# 导入 save 模块
# 导入后 save 就成为模块aa中的一个变量,对应一个模块对象
import save
fee = input('请输入午餐费用:')
members = input('请输入聚餐人姓名,以英文逗号,分隔:')
# 将人员放入一个列表
memberlist = members.split(',')
# 得到人数
headcount = len(memberlist)
# 计算人均费用
avgfee = int(fee) / headcount
print(avgfee)
# 使用 模块save里面的 savetofile 函数
save.savetofile(memberlist, avgfee)
方法二
还可以在 aa.py 里面 通过 from import 关键字导入其它模块里面的标识符(包括变量名和函数名等)。
导入之后,这些其它模块的变量名和函数名就成为 模块aa 里面 变量名,函数名了。
这样,我们就可以直接使用它们了。
完整代码如下:
# 从 save 模块 导入标识符 savetofile ,
# 导入后 savetofile 就成为模块aa中的一个变量,对应一个函数对象
from save import savetofile
fee = input('请输入午餐费用:')
members = input('请输入聚餐人姓名,以英文逗号,分隔:')
# 将人员放入一个列表
memberlist = members.split(',')
# 得到人数
headcount = len(memberlist)
# 计算人均费用
avgfee = fee / headcount
print(avgfee)
# 直接使用 savetofile 函数
savetofile(memberlist, avgfee)
一些技巧
如果在一个模块文件中需要导多个其它模块,可以分开写导入语句,像这样
也可以一起导入,模块之间用逗号隔开,像这样
如果我们要从1个模块里导入多个标识符,可以这样
如果我们要导入1个模块里面的很多个标识符,可以使用*代表所有可导入的标识符(包括变量名,函数名等)
这里 import * 把aa模块所有可以导入的对象全部都导入了。
如果我们需要从两个模块导入函数,恰好这两个函数是同名的,这是我们可以给其中一个起个别名,避免冲突,比如
注意点
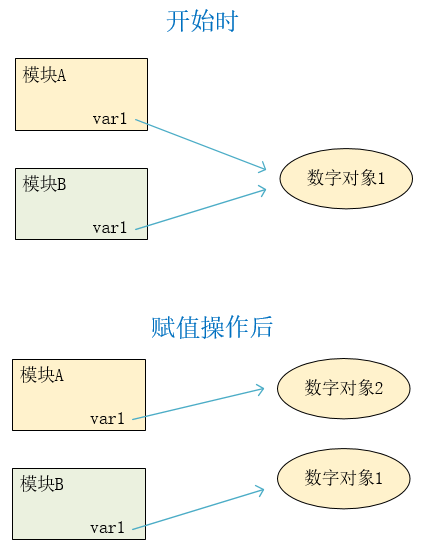
当一个b模块从a模块导入了名字 var1 后,注意,b模块和a模块 是 各自有一个 名为 var1 的变量 , 而不是两个模块共享一个 名为 var1 的变量。
我们看下面的一个例子
有一个模块文件 a.py,如下
另外一个模块文件 b.py, 从a中导入了名字 var1 ,如下
当我们执行 b.py 时,显示结果如下
发现没有?
虽然 b模块 从 a模块 导入了名字 var1, 但是a模块和b模块中的 var1 是两个不同名字 。
在刚刚执行导入时,这两个var1指向同一个对象,但是后来可以通过赋值语句,分别指向不同的数据对象。
这个过程如图所示
如果要在多个模块中共享同一个数据对象,并且这个数据对象的值将来可能会改变。
即使共享的只是一个数字或者字符串变量, 也应该放在一个值可以变动的对象类型中。 比如:列表, 或者后面要学习的 字典 和 自定义类型。
我们再试一下:
模块文件 a.py,如下
另外一个模块文件 b.py, 如下
当我们执行 b.py 时,显示结果如下
将模块放入包中
当我们的项目模块文件特别多的时候,我们还需要将这些模块文件根据功能划分到不同的目录中。
这些放模块文件的目录,Python中把他们称之为 包 (Package) 。
在 Python 3.3 以前的版本,包目录里面需要有一个名字为 __init__.py 的初始化文件,有了它,Python才认为这是一个Python包。
通常,这个初始化文件里面不需要什么代码,一个空文件就可以了。
当然你也可以在里面加入代码,当这个包里面的模块被导入的时候,这些代码就会执行。
Python 3.3 以后版本的解释器, 如果目录只是用来存放模块文件,就不需要一个空的 __init__.py 了。
但是 __init__.py 可以作为包的初始化文件,里面放入一些初始化代码,有独特的作用。这个英文帖子有细致的描述,感兴趣的朋友可以阅读一下。
下面是一个商城产品目录结构的例子(点击这里下载代码zip包)
stock/ --- 顶层包
__init__.py --- stock包的初始化文件
food/ --- food子包
__init__.py
pork.py
beef.py
lobster.py
...
furniture/ --- furniture子包
__init__.py
bed.py
desk.py
chair.py
...
kitchen/ --- kitchen子包
__init__.py
knife.py
pot.py
bowl.py
...
最上层的是stock包,里面有3个子包 food、furniture、kitchen。
每个子包里面的模块文件都有名为stockleft的函数,显示该货物还剩多少件。
如果我们要调用这些模块里面的函数,可以像这样:
我们也可以使用from...import… 的方式,像这样
库的概念
如果你写的 模块文件 里面的函数, 实现了通用的功能,经常被其它模块所调用, 我们就可以把这些被调用的模块文件称之为 库
库是个抽象的概念,只要 某个模块 或者 一组模块 , 开发它们的目的 就是给 其它模块调用的,就可以称之为库。
Python标准库
Python语言提供了功能丰富的标准库 。 这些标准库把开发中常用的功能都做好了。
我们可以直接使用它们。
这些标准库里面 有一部分叫做 内置类型 built-in types) 和 内置函数 (built-in functions) 。
内置类型 和 内置函数 无须使用import导入,可以直接使用。
内置类型有:int、float、str、list、tuple等
内置函数前面我们介绍过,可以在Python的官方文档查看到,点击这里查看。
比如像 int,str,print,type,len 等等
还有些标准库,需要使用import导入,才能使用。
常见有 sys, os, time, datetime, json,random 等
比如,我们要结束Python程序,就可以使用sys库里面的exit函数
比如,我们要得到字符串形式的当前日期和时间,可以使用datetime库
import datetime
# 返回这样的格式 '20160423'
datetime.date.today().strftime("%Y%m%d")
# 返回这样的格式 '20160423 19:37:36'
datetime.datetime.now().strftime("%Y%m%d %H:%M:%S")
比如,我们要获取随机数字,可以使用random库
解释器怎么寻找模块文件?
边看下面两个视频讲解,边学习以下内容
当Python解释器执行
或者
这样的语句时, Python 解释器是到什么地方查找模块文件xxx的?
内置模块
它首先在解释器 内置模块 ( builtin modules ) 中寻找 是否有 xxx。
所谓内置模块,就是内置在Python解释器程序中的模块,它们是用C语言编写,编译链接在解释器里面。
也就是说它们就是解释器的一部分,所以解释器运行时,它们就在解释器里面,无需查找。
比如:time, sys, gc, math, mmap等,就是内置模块
大家可以通过 sys.builtin_module_names的值来查看哪些模块是直接包含在解释器里面的。
很容易把 内置模块 和前面提到的 内置类型、内置函数 这些名词搞糊涂。
我特地在 Stack Overflow 上 提出过这个问题
根据专家的解释 :
概念上 内置类型、内置函数 应该也是属于 内置模块的,在名叫 builtins 的内置模块里面。
内置类型、内置函数 因为它们特别常用,所以被解释器特别优待,可以无需导入直接使用。
sys.path
如果内置模块没有 xxx 这样的名字 ,接下来到什么地方查找?
Python的 sys 库 里面有个属性 path。你可以运行下面的语句看看 sys.path 的内容
通常可以得到类似下面这样的结果
C:\projects\first
C:\Python\Python36\python36.zip
C:\Python\Python36\DLLs
C:\Python\Python36\lib
C:\Python\Python36
C:\Python\Python36\lib\site-packages
这个 sys.path 是一个列表,这个列表里面包含了一些 路径 。
当我们import 一个模块时 ,解释器会 依次到 sys.path 包含的目录下去寻找 有没有同名的模块 。
那么, sys.path 里的路径是怎么来的呢?
解释器启动的时候,是从根据下面这些规则 添加路径到 sys.path 列表里的
- 启动脚本文件所在的目录
启动脚本就是执行Python程序后面 的参数 脚本文件。
比如 python d:\mydir\first.py 那么这个 first.py 就是 启动脚本文件, 脚本文件所在的目录 ,这里就是 d:\mydir 会被加到 sys.path 中作为模块搜索路径。
如果启动命令行,没有指定脚本文件,而是像这样 python ,直接 启动了 python 交互命令行,
或者 像这样 python -m pytest [...] 通过 -m 参数 执行某个模块,
那么 当前工作目录 会被加到 sys.path 中作为模块搜索路径。
- PYTHONPATH 环境变量里的目录
我们可以在 PYTHONPATH 环境变量里面添加上 多个目录作为 模块搜索路径。 多个目录之间的分隔符根据操作系统而定。 Windows下面是分号,Linux下面是冒号。
解释器启动的时候 , PYTHONPATH 环境变量里的目录 会被加到 sys.path 中作为模块搜索路径。
- Python解释器的 缺省安装目录(installation-dependent default)
比如: Windows下面就是 在 解释器安装目录中的 lib/site-packages 目录。
如果我们自己想添加一些目录,作为模块搜索路径,怎么办呢?
一种方法是:把这些目录加到环境变量 PYTHONPATH 里。
因为Python解释器在启动后,会把 环境变量PYTHONPATH里包含的目录,自动添加到sys.path的路径列表里面。
比如,在windows下面,我们可以用这样的命令添加
那么解释器启动后, c:\myproject 和 c:\myproject\mylib 这两个目录就被添加到了sys.path里面。
注意这样的环境变量添加,只在当前命令行窗口有效。重新打开窗口就会失效了。
如果要确保持久有效,可以添加在windows 的 环境变量设置对话框中。
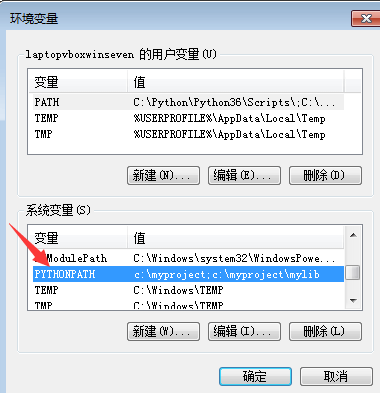
有上述的模块搜索路径的概念,接下来我们再来看一个例子。
如果我们有一个python 模块文件名为 m1,放在目录 d:\project\libs\p1\p2 下面
我们要在代码中这样写
或者
为了让解释器能正确的找到 m1 这个模块,我们应该把什么路径加到sys.path 中呢?
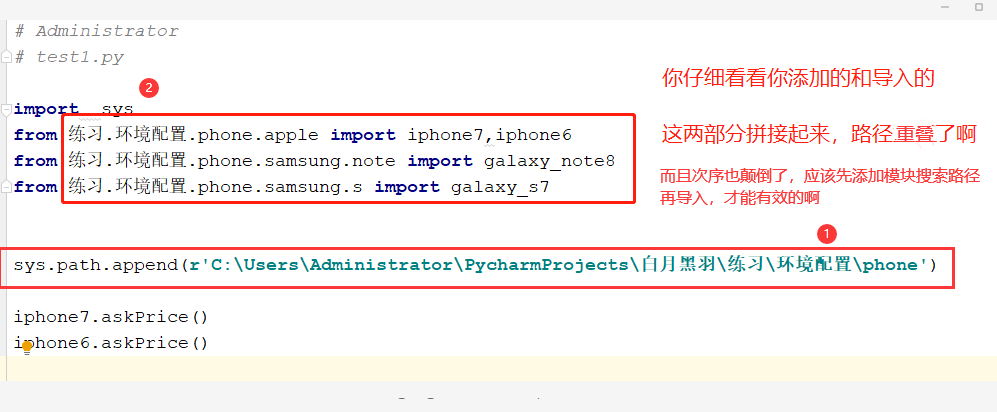
有些实战班学员会这样写
如果,这样写,就会到目录 d:\project\libs\p1 下面找 有没有 p1\p2\m1 这样的三级目录文件结构。 显然时不对的。
应该这样写
注意: 模块搜索路径 和 import 后面的路径合起来是一个完整的路径
在和小班学员的指导过程中,发现很多学员对 环境变量 没有概念。
了解环境变量非常重要,不仅仅是Python编程需要了解它,请点击这里,观看关于环境变量的视频讲解
自己想添加一些目录,作为模块搜索路径,还有一种方法:
就是在代码中直接修改sys.path,使用 append 或者 insert方法,把目录直接添加到该列表中。
使用这种方法 同样要注意:
-
sys.path.append 添加的模块搜索路径 和 import 后面的路径合起来是一个完整的路径
-
必须先 append, 然后再 import ,否则import时 还没有设定好模块搜索路径
而我们一个实战小班的学员, 一次练习就同时犯了2条错误,如下所示
安装其他的库
Python 之所以这么流行,就是因为它有太多的优秀的第三方库和框架。
有了这些库,Python才能在各行各业都这么受欢迎。因为这些库极大的提高了开发效率。
要使用这些库,我们需要安装到本地。
在Python中,安装第三方库,通常是使用pip命令。
那些优秀的第三方库,基本都是放在一个叫 PYPI 的网站上
pip命令会从该网站下载这些库的安装包进行安装。
例如,如果我们要安装 requests库,可以执行如下的命令
我们在国内,使用pip 安装的时候,可能由于网络原因,到国外访问 PYPI 会比较慢。
而国内有网站(比如 百度/清华大学 等)对PYPI 做了镜像备份。
我们可以通过在命令中加上参数 -i https://pypi.tuna.tsinghua.edu.cn/simple ,这样就指定使用 清华大学源 作为安装包的下载网站。
如下所示:
如果pip安装库的时候,出现SSL错误,可能是网络对 https证书 校验的问题,可以改用 http协议 下载,如下所示
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
注意,很多初学者会在python shell里面执行pip命令,像这样
这个命令是一个程序,不是Python语句,要在cmd 命令行中直接执行,像这样
安装好以后,我们就可以使用import去导入这些库并且使用了